Installation¶
Install the current PyPI release:
$ pip install metacluster==1.3.0
Install directly from source code:
$ git clone https://github.com/thieu1995/metacluster.git $ cd metacluster $ python setup.py install
In case, you want to install the development version from Github:
$ pip install git+https://github.com/thieu1995/permetrics
After installation, you can import MetaCluster as any other Python module:
$ python
>>> import metacluster
>>> metacluster.__version__
Examples¶
Let’s go through some examples.
First, load dataset. You can use the available datasets from MetaCluster:
# Load available dataset from MetaCluster from metacluster import get_dataset # Try unknown data get_dataset("unknown") # Enter: 1 -> This wil list all of avaialble dataset data = get_dataset("Arrhythmia")
Load your own dataset if you want:
import pandas as pd
from metacluster import Data
# load X and y
# NOTE MetaCluster accepts numpy arrays only, hence use the .values attribute
dataset = pd.read_csv('examples/dataset.csv', index_col=0).values
X, y = dataset[:, 0:-1], dataset[:, -1]
data = Data(X, y, name="my-dataset") # Set up the name for dataset as saved path of model
Next, scale your features:
# MinMaxScaler data.X, scaler = data.scale(data.X, method="MinMaxScaler", feature_range=(0, 1)) # StandardScaler data.X, scaler = data.scale(data.X, method="StandardScaler") # MaxAbsScaler data.X, scaler = data.scale(data.X, method="MaxAbsScaler") # RobustScaler data.X, scaler = data.scale(data.X, method="RobustScaler") # Normalizer data.X, scaler = data.scale(data.X, method="Normalizer", norm="l2") # "l1" or "l2" or "max"
Next, select Metaheuristic Algorithm, Its parameters, list of objectives, and list of performance metrics:
list_optimizer = ["BaseFBIO", "OriginalGWO", "OriginalSMA"] list_paras = [ {"name": "FBIO", "epoch": 10, "pop_size": 30}, {"name": "GWO", "epoch": 10, "pop_size": 30}, {"name": "SMA", "epoch": 10, "pop_size": 30} ] list_obj = ["SI", "RSI"] list_metric = ["BHI", "DBI", "DI", "CHI", "SSEI", "NMIS", "HS", "CS", "VMS", "HGS"]
You can check all supported metaheuristic algorithms from: Mealpy Link. All supported clustering objectives and metrics from: Permetrics Link.
If you don’t want to read the documents, you can print out all of the supported information by:
from metacluster import MetaCluster
# Get all supported methods and print them out
MetaCluster.get_support(name="all")
Next, create an instance of MetaCluster class and run it:
model = MetaCluster(list_optimizer=list_optimizer, list_paras=list_paras, list_obj=list_obj, n_trials=3) model.execute(data=data, cluster_finder="elbow", list_metric=list_metric, save_path="history", verbose=False) model.save_boxplots() model.save_convergences()
As you can see, you can define different datasets and using the same model to run it. Remember to set the name to your dataset, because the folder that hold your results is the name of your dataset.
Visualization¶
If you set save_figures=True in the 4th step, you can get a lots of figures that automatically saved in the save_path.
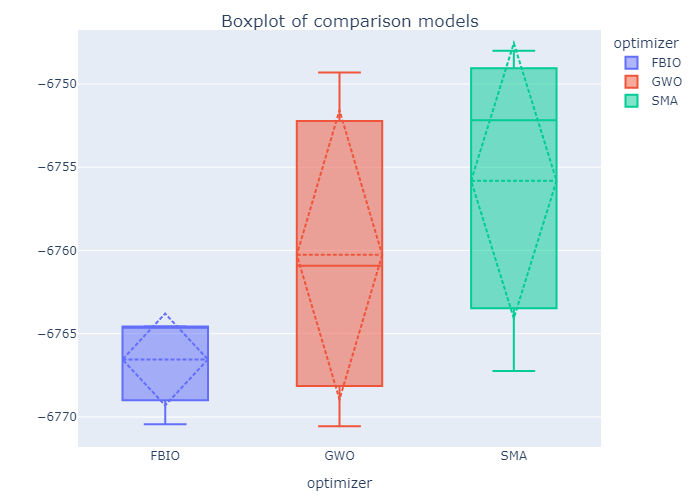
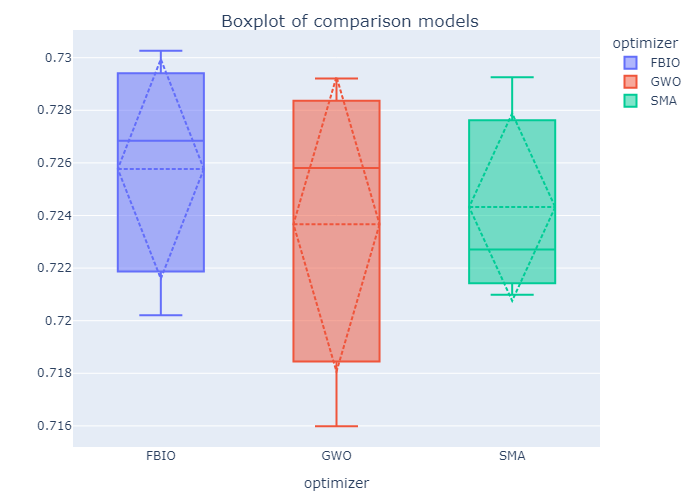
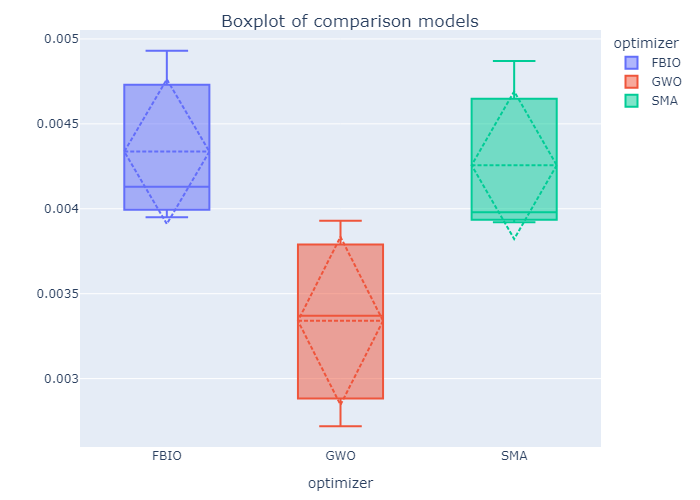
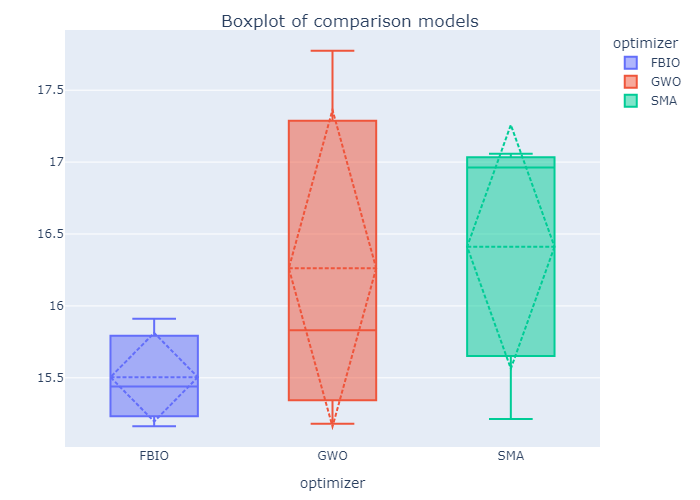
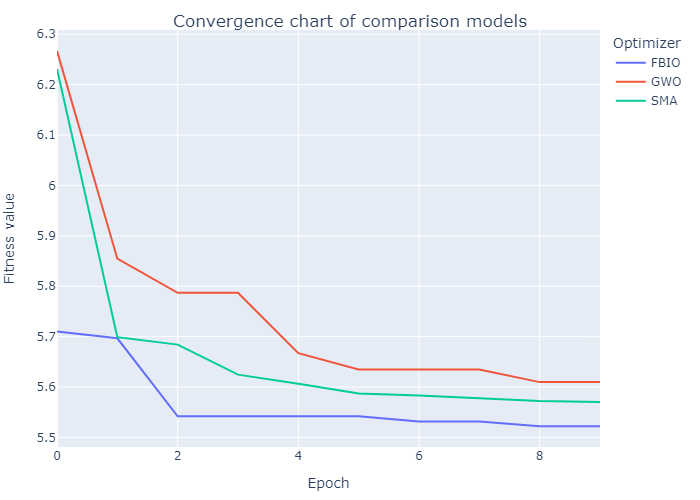
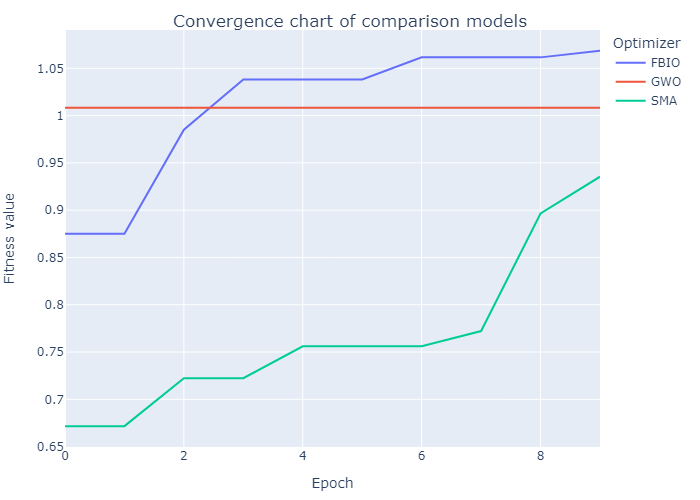
Also you will get a lots of csv file like this.
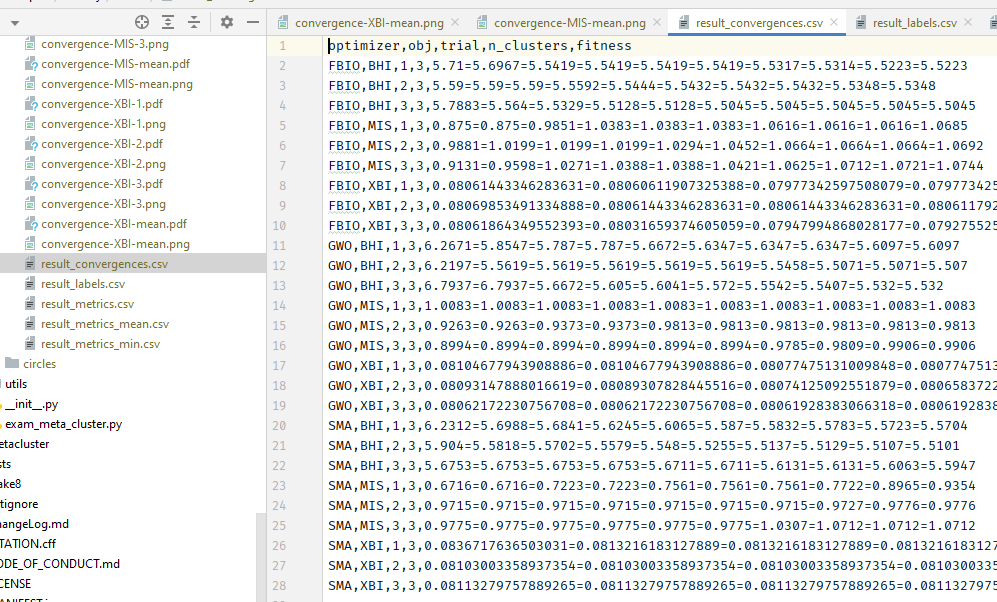
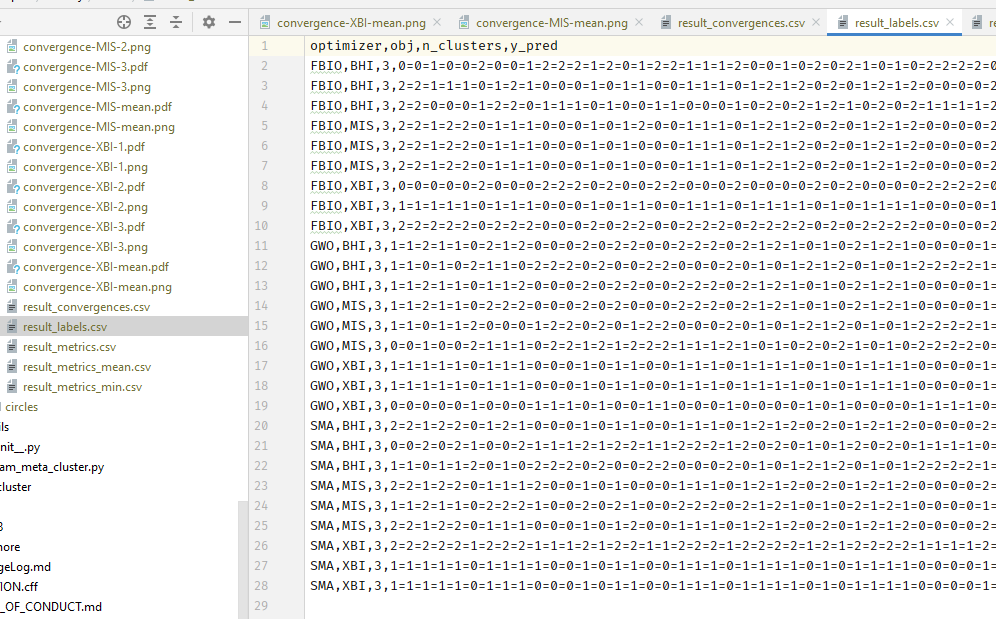
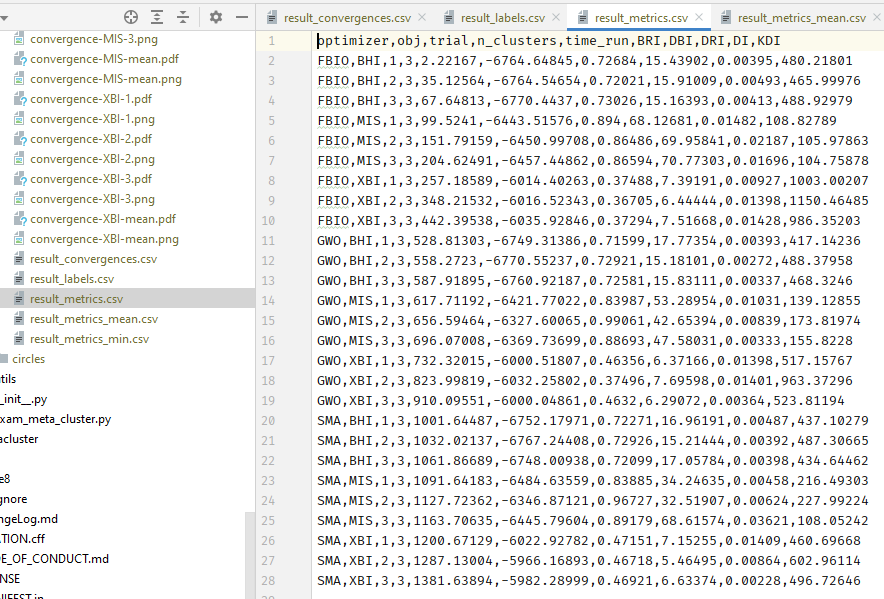
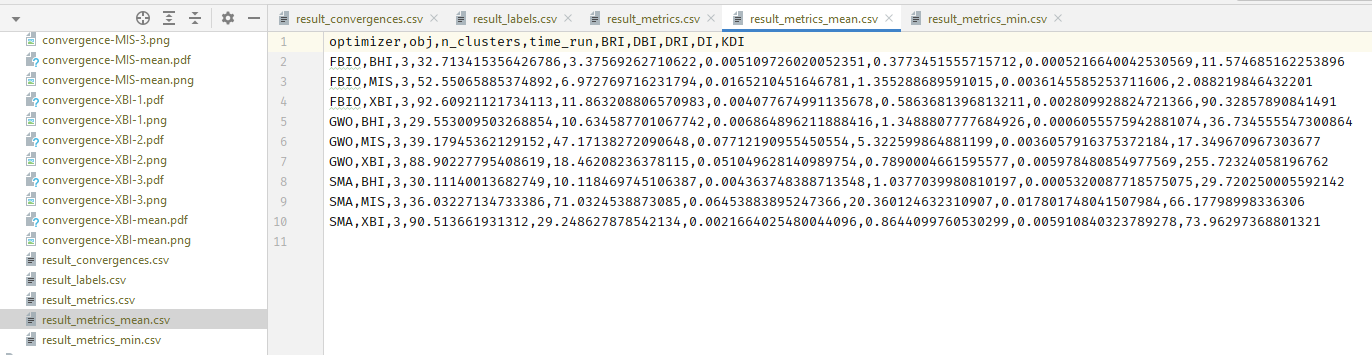

Note that, there are two special files which are result_convergences.csv and result_labels.csv. You will see a lots of symbol = in these files.
We did that intentionally because we need to save all fitness value after N epochs as fitness column and all labels of predicted X as y_pred column. So it will be easier for users when they read these csv files.
Here is an simple example how to read these files:
import pandas as pd
df = pd.read_csv("path_save/result_convergences.csv")
# I want to get the loss convergence of model FBIO, with objective BHI and at the 1st trial
res = df[(df["optimizer"]=="FBIO") & (df["obj"]=="BHI")]["fitness"].values
list_convergences = np.array(res.split("="), dtype=float)